这篇文章简要介绍联邦学习、联邦强化学习、独占式联邦强化学习及其相关知识,本文搬运自我的毕设论文《联邦强化学习算法的研究与实现》的答辩稿。
引言
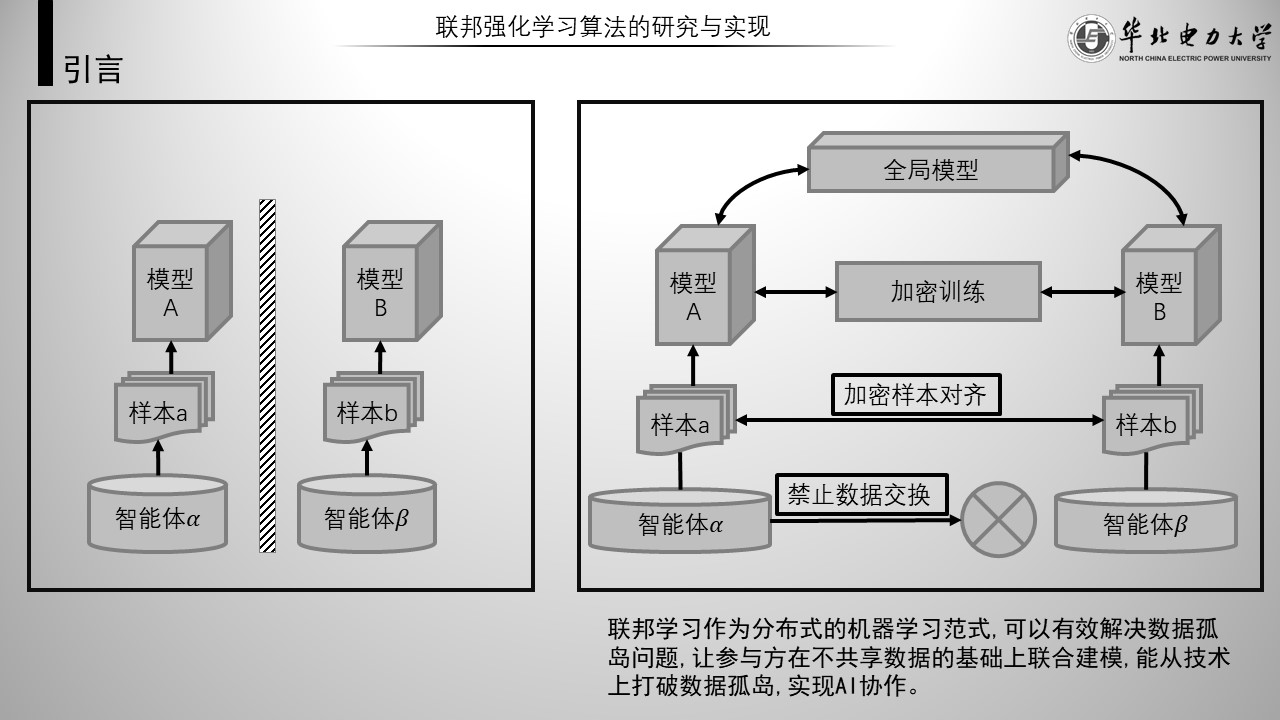
如今机器学习几乎成为所有企业的必备技能,通常机器学习模型的能力大致与计算速度和训练数据量成正比。在数据量上,除了自己大量收集数据外,还可以与别人共享数据。可是受限于用户隐私、数据安全和政府法规,在互联网上出现了许多数据孤岛。
如左图,每个孤岛只能在自己的数据集上进行训练。对于拥有数据量较少的公司,数据量的壁垒会让其在机器学习的竞争上愈加处于劣势。
于是联邦学习应运而生,其在不直接共享原始数据的情况下,打破了数据孤岛。如右图是一种常见的联邦学习示意图。
当然联邦学习不是完美的解决方案,论文就从一种联邦学习的实现——联邦强化学习入手,研究这种算法,在提升安全性和提供多样化计算形式上对其进行创新。
主要工作
论文主要工作有理论和实践两大部分。
- 理论部分包括:学习联邦强化学习及其相关知识,对联邦强化学习在防御能力上进行改进,设计实验系统。
- 实践部分包括:实现实验系统,实现并分析上述各种算法。
- 学习的内容有:联邦学习、深度强化学习、针对模型窃取的攻击及防御、针对样本窃取的攻击及防御、针对模型功能的攻击及防御、拆分学习以及联邦强化学习。
独占式联邦强化学习和实验系统都是本文的创新内容。

联邦学习
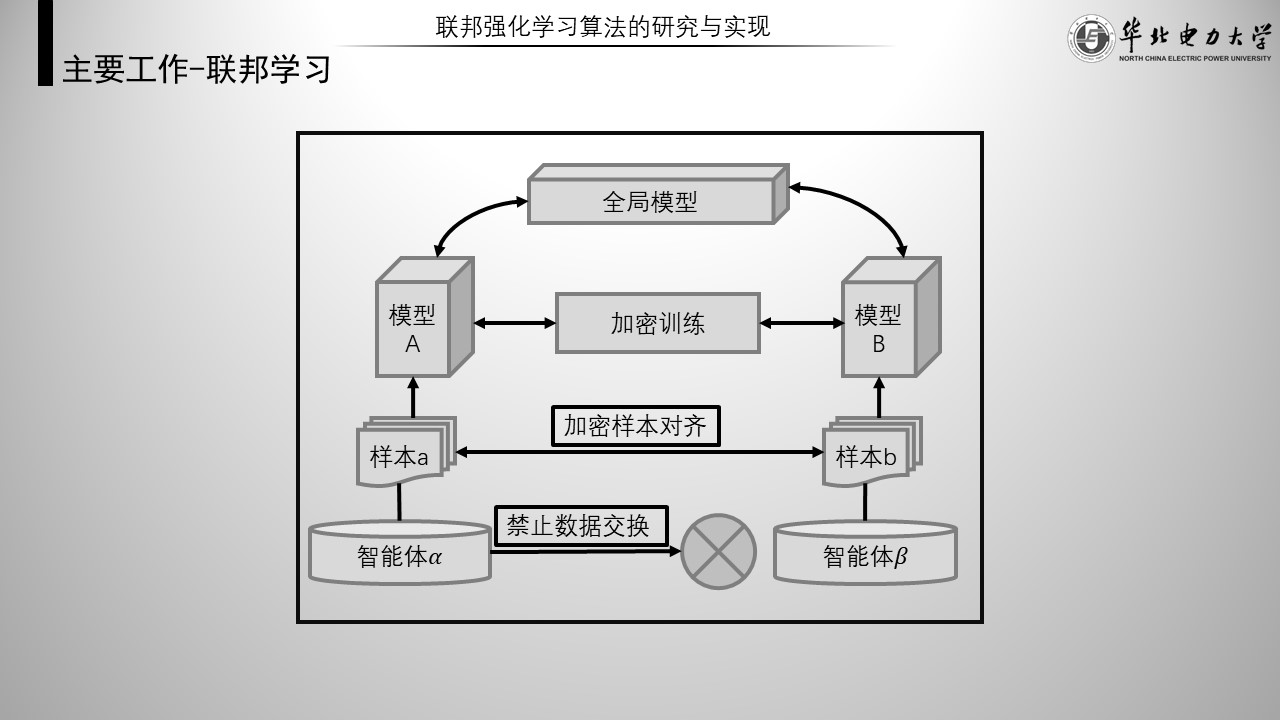
联邦学习是一种机器学习设置,或者说一种上层框架,表示多个智能体在中央服务器或服务提供者的协调下协作解决机器学习问题,而每个智能体的原始数据存储在本地,智能体只与服务器交互用于更新模型的必要信息。联邦学习需要一种具体的算法填充下层结构。
如图,是一种普通分类器的联邦学习示意图。
深度强化学习
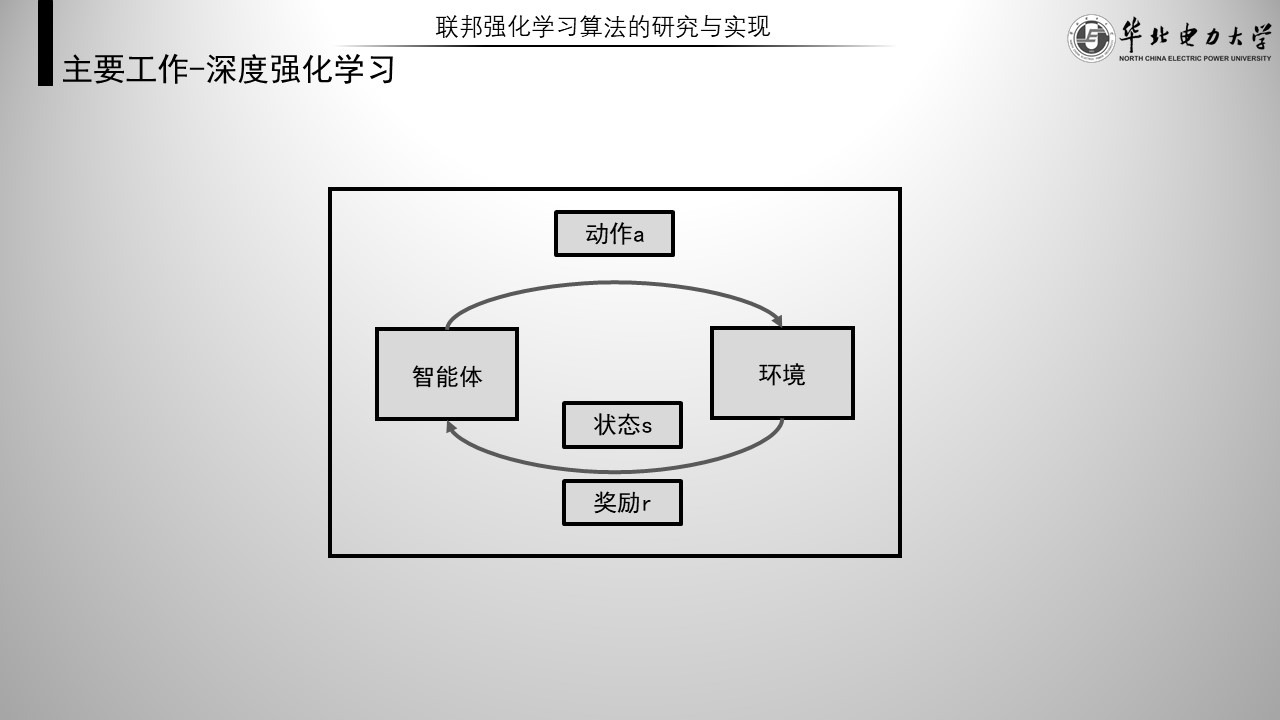
强化学习基本示意图如图,强化学习与其他机器学习算法最大的区别在于其拥有 “ 环境 ” 与 “ 激励 ” 。
大致过程如下,在某个状态,智能体通过Q-table,或者说策略,来预测下一次动作,执行动作后来到新的状态并获得环境的反馈,也就是激励。智能体根据激励更新Q-table,就完成了一次强化学习。而智能体的目标就是使全局激励和最大。
由于许多问题状态集很大,没法用表格记录,于是出现了用神经网络代替Q-table。再进行一些优化就成为了深度强化学习。
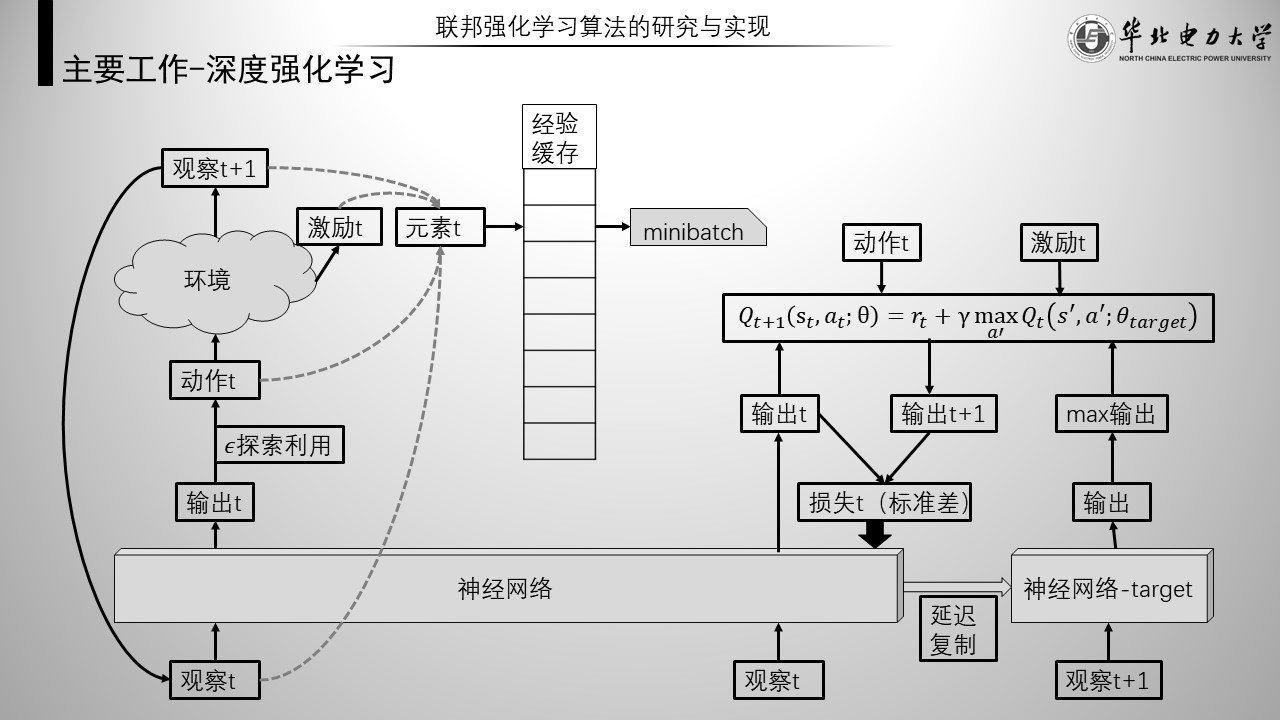
本文采用的是Double DQN深度强化学习算法。具体流程如图。
如图左部分是预测阶段,右部分是训练阶段。一般预测10个单位时间,就训练一次。预测阶段的每一轮观察、动作、激励以及后一次观察作为元素存入经验缓存。训练阶段随机抽取一部分元素进行训练。更新公式在右侧。一般的深度强化学习使用同一个网络更新q值,double-DQN采用一个延迟复制的target网络来更新q值,根据初步实验,可以基本验证这种方式更不容易过拟合。最后,本体网络输出的Q值与更新后的q值做标准差,就是该网络的损失函数。以上就是本文采用的double DQN深度强化学习算法。
攻防
接下来简要介绍在联邦学习上,针对三个不同方面的攻防措施。
- 针对窃取模型的攻击方式有模型窃取攻击,相应的防御措施有模糊置信度。
- 针对窃取样本的攻击方式有差分攻击、模型反演攻击,相应的防御措施有差分隐私。
- 针对破坏模型功能完整性的攻击方式有后门攻击,相应的防御措施有客户端级差分隐私。

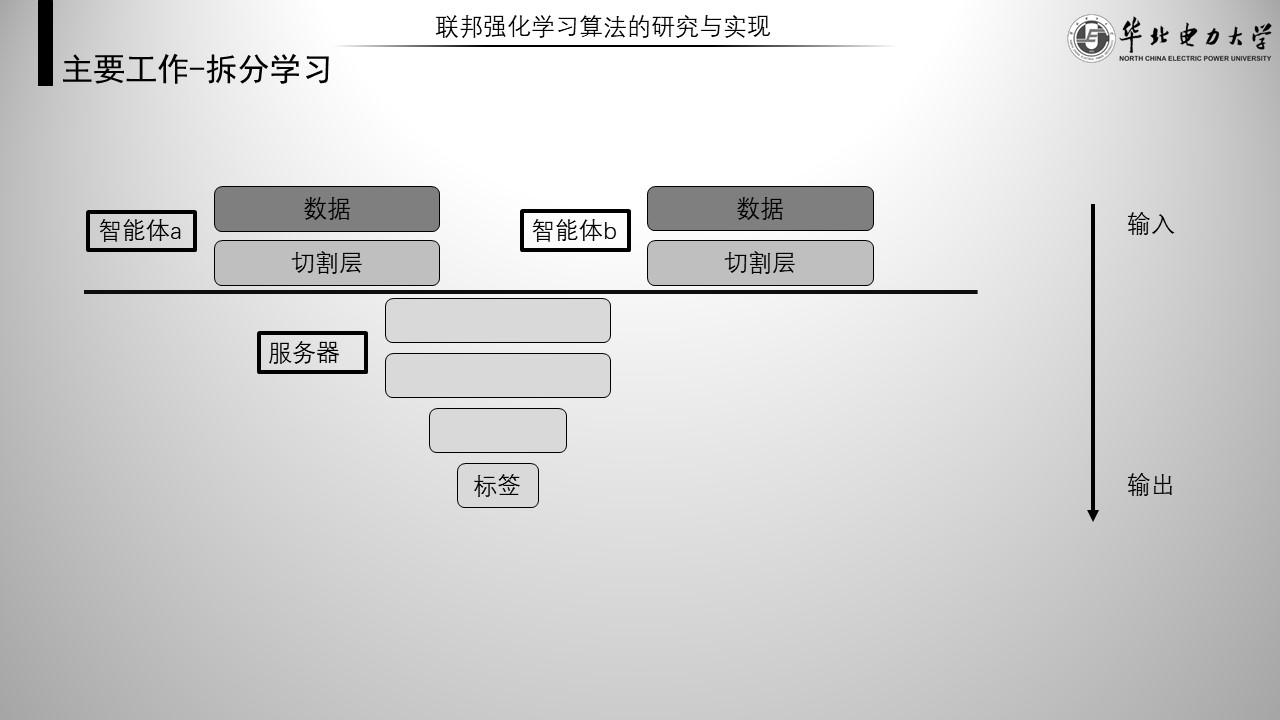
拆分学习
普通拆分学习示意图如图,拆分学习将一个完整的神经网络一分为二,一部分交由智能体维护,一部分交由服务器维护。
每个智能体拥有自己本地的半个神经网络,服务器拥有唯一的半个网络,两部分网络串联后即可进行训练。这是一种与联邦学习并驾齐驱的分布式学习设置。拆分学习中,由于智能体无法获得上层模型的任何信息,所以针对智能体本地模型的攻击几乎无从下手。
联邦强化学习
联邦强化学习的引入不仅在于联邦学习本身的优点,即间接扩充训练样本以提高模型能力,还在于,联邦强化学习可以让能够获得激励的智能体帮扶不能够获得激励的智能体进行学习。
联邦强化学习整体网络结构如左图,其是一种上层框架使用联邦学习,下层填充强化学习的一种具体算法。其中联邦学习的实现使用的是多层感知器,其将两个智能体的输出作为输入,输出一个新的q值。
如右侧,以智能体alpha为例。第一个式子表示,进行强化学习不使用Q网络的输出,而是使用Q网络与MLP串联后的输出Q f作为Q值。其Q函数中将beta的输出C beta当作常数进行运算。下面是它的更新公式和损失函数。
另外,本文隐私保护机制采用是高斯差分隐私,即智能体在Q网络的输出上加入高斯噪声后再与服务器进行交互。
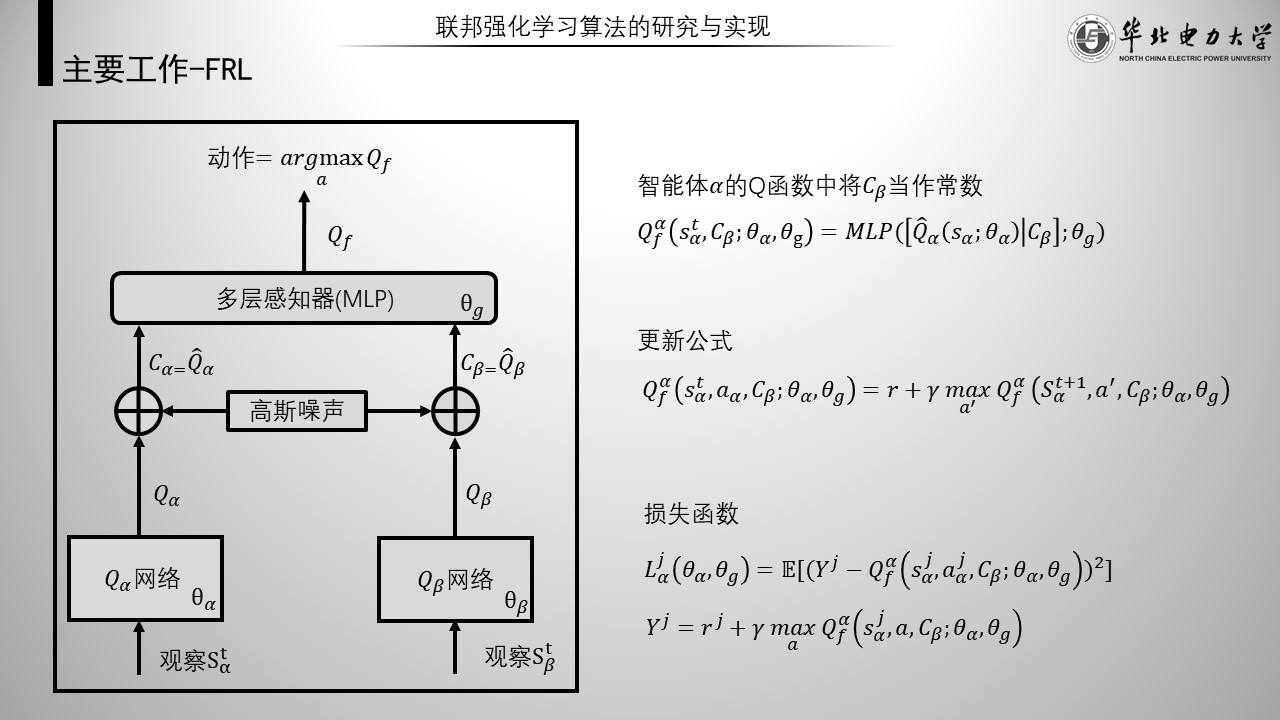
然后说一下细节,为了避免歧义,这页展示的是智能体alpha与beta的本地网络。
另外,本文采用不对等的节点形式,即没有单独的服务器,而是其中某个节点充当服务器计划训练任务,但要求该节点能够获得激励。后文默认智能体alpha计划训练任务,beta无法获得激励。

这页说明为什么联邦强化学习可以做到帮扶。
遮罩的部分是无法获得激励的智能体无法维护的部分,但是只要它能够获得蓝色圆圈——输出t+1,它依然能够进行预测和训练。当模型精度达到一定程度后,其还可以脱离联邦框架,在本地,只进行预测。

独占式联邦强化学习
这是论文的主要创新部分。
引入独占式的目的有:
- 提升针对模型窃取和模型功能的防御能力
- 提供多样化计算形式,如:算力交易
- 任务发起者需要他人帮助,但不想泄露模型或者模型目的。

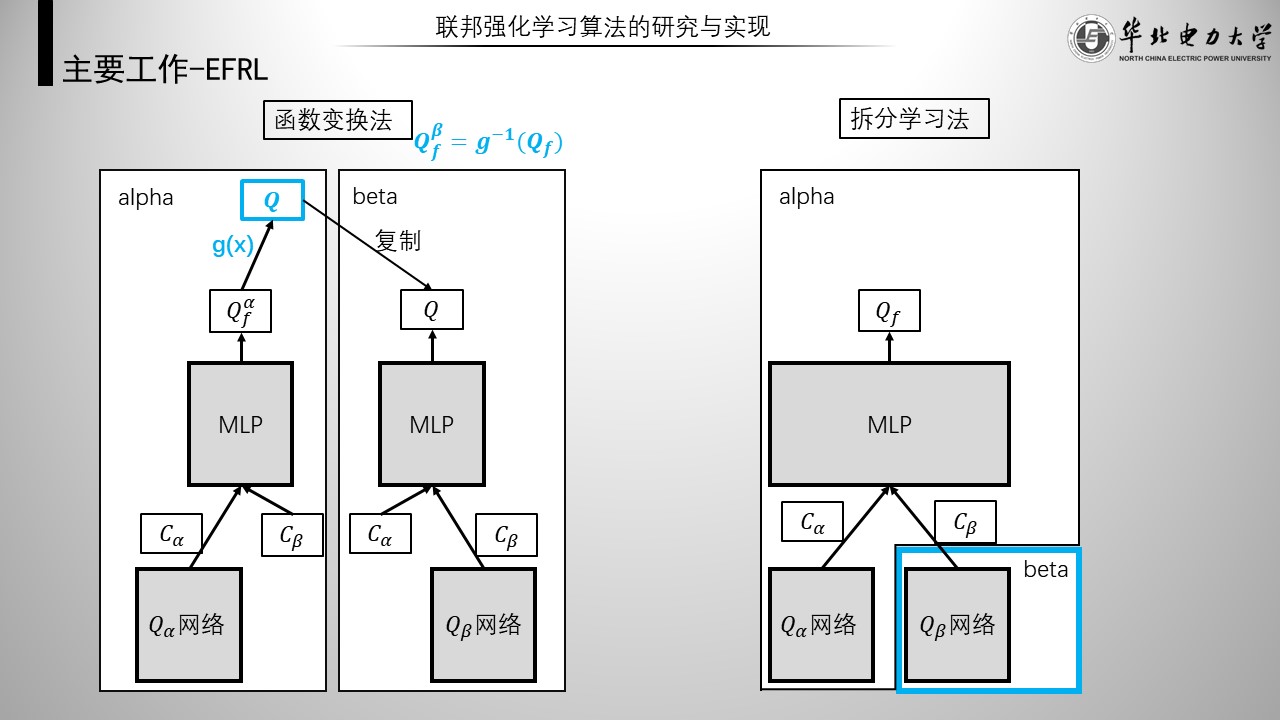
接下来,本文提出的两种独占式联邦强化学习算法。
如左图,从模型功能完整性出发,是函数变换法独占式联邦强化学习。关键点是,在智能体beta的输出后方添加gx函数,而gx函数由alpha维护。这时beta训练的整体模型就变成了qf对gx的逆。通过设计gx,可以让beta无法获得功能正确的模型,alpha从而使模型相对于beta保持独占
如右图,从模型完整性出发,是拆分学习法独占式联邦强化学习。关键点是,智能体beta只拥有原来的q网络,mlp仅由alpha维护。但是由于联邦学习框架的存在,这里的q网络不具有任何意义,alpha从而使模型相对于beta保持独占。
实验系统
实验系统一共有5个部分:
- main:负责统筹训练任务,整理输出结果。
- agent:负责计划联邦学习的本地任务,类似智能体。
- dqn-network:负责训练网络,类似智能体的一个计算模块。
- replay-memory:负责经验缓存,是DQN需要的额外模块。
- environment:负责模拟真实环境,是强化学习必备的一个模块。

将main中模块换成其他机器学习,main依然可以为其进行标准化输出,其中一共设置了47个自定义参数,可以提供多样化的测试条件。agent若装备dqn-network和replay-memory,即可获得DQN学习的能力,当然agent可以填充其他类型的学习模块。而agent与environment的交互过程就是强化学习的过程。
实验场景
本实验模拟的是走迷宫游戏。
规则有:两个智能体的目标是相遇。激励系数变化激励为两智能体的曼哈顿距离。稀疏激励有走到空地得-1、撞墙得-10、相遇得50,并结束本轮游戏。
图中可以看到alpha的观察窗口为5乘5的矩阵,而beta则是3乘3的矩阵。其他具体实验设置可以参考论文。

运行结果
本实验使用python语言在pytorch平台上进行编程,最后运行在Linux操作系统中。源代码已经放在GitHub上了。
实验结果
经过整理,实验结果如图。
这页展示的是实现联邦强化学习算法的实验结果
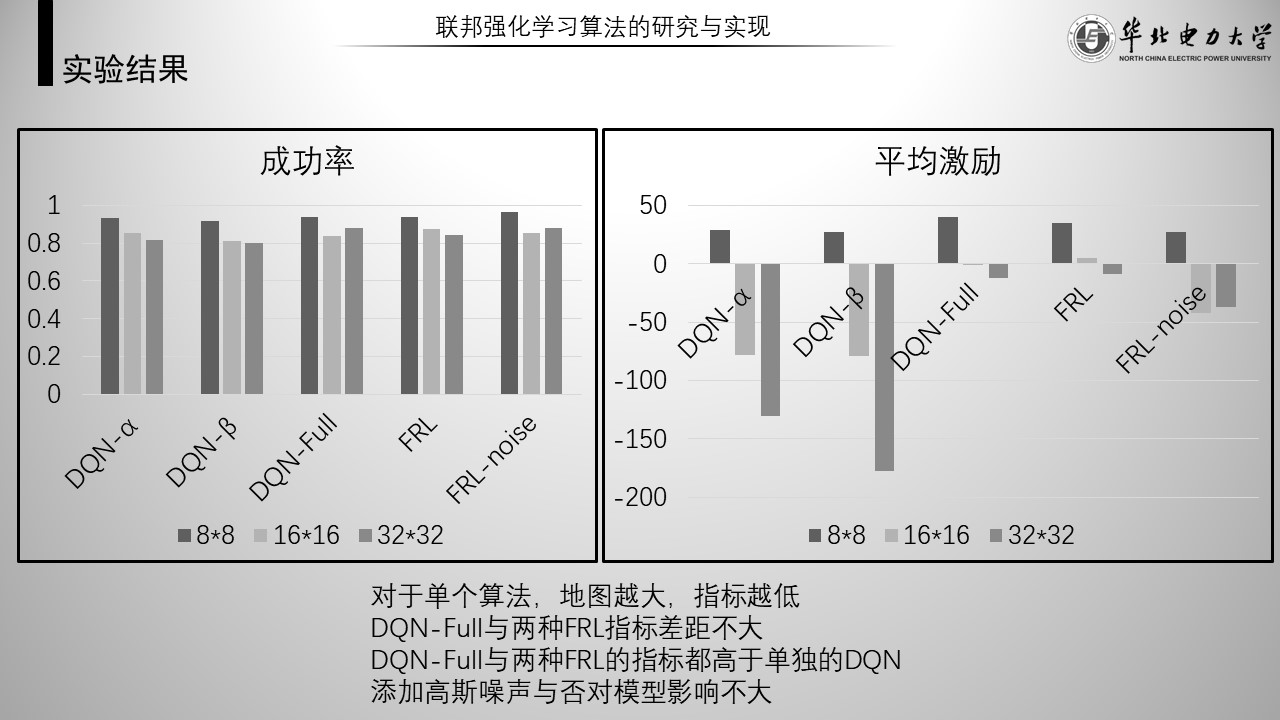
一共比较了5中算法。分别是仅使用alpha Q网络的DQN alpha、仅使用beta Q网络的DQN beta、不考虑数据隐私的DQN full以及是否加入高斯噪声的两种FRL。前三种算法是基线。
每个算法都分别在不同大小的地图进行了评估,使用了两个指标,分别是成功率与平均激励,均是值越大越好。
- 在地图大小上,可以看到基本每种算法的成功率和平均激励都与地图大小成反比,这符合预期,因为地图越大,任务就越复杂,成功率和平均激励理应越低。个别数据异常的原因可能是过拟合。
- 两种FRL与DQN full算法指标差距不大,由于DQN full是一种不考虑数据隐私的数据集中式算法,说明FRL在做到保护数据隐私的前提下保证了训练效果。
- DQN full和两种FRL的指标均高于两种单独的DQN算法,平均激励的提升最明显,这说明FRL确实让两个智能体互相做到了帮助与帮扶。
- 比较两种FRL的指标,可以看到添加高斯噪声与否,对于模型的影响不大。
这页展示的是实现独占式联邦强化学习算法的实验结果

实验默认使用了高斯噪声,于是采用FRL-noise作为基线。
可以看到两种独占式算法的指标与FRL-noise差距不大。说明独占式算法几乎没有牺牲模型的精度。再看两个测试结果。测试实验使用被独占的智能体的网络进行测试。可以看到两种算法的测试结果指标都非常低,几乎等同于刚初始化的网络。可以说明独占式算法确实做到了模型的独占。